June 10, 2025: Millions of users worldwide were affected in conversational AI. Starting in the early hours of the U.S. morning and spreading across Europe, South Asia, and the rest of the world, the main ChatGPT platform created by OpenAI was mostly unavailable. This post will take us through the events that occurred, the effects on people and enterprises, and crucial lessons to anyone who uses AI services in their daily business. We’ll also make a lighter glance at the memes and tweets that the outage prompted.
Who Got Caught in the Jam
- Students & Creators
- Businesses
- Developers.
Individual Users: Students, content writers, and ordinary chat lovers were unable to finish their essays, debug code, or even merely enjoy the conversations they had gotten used to.
Enterprises & Businesses: Workflows for companies that utilize ChatGPT to enable automatic report generation, internal knowledge bases, and customer-support chatbots were banned, forcing at least some teams to halt launches or switch back to manual solutions.
Third-Party Integrations: Depending on the significance of real-time response to their functionalities, applications and services developed using the OpenAI API, such as the well-known research assistants, learning platforms, and productivity tools, either gracefully degraded or stopped working completely.
Identifying the Primary Cause
OpenAI has termed the event as a “partial outage that was made worse by an abnormally high number of simultaneous requests.”
As of June 11, 2025, no comprehensive post-mortem has been released; nonetheless, the following significant findings can be noted:
Infrastructure Overload: It’s possible that the simultaneous flood of users from several time zones overwhelmed some of the service clusters’ load-balancing metrics.
The implementation of the basic chat capabilities was prioritized in order to recover, but the secondary services (voice chat, file uploads, and image production) were frequently neglected. This suggests that the service design was tiered.
Monitoring Gaps: The almost three-hour delay between when users first noticed issues and when the first status message was posted publicly means that there is a possibility to improve the real-time notifying of outages and informing the customers
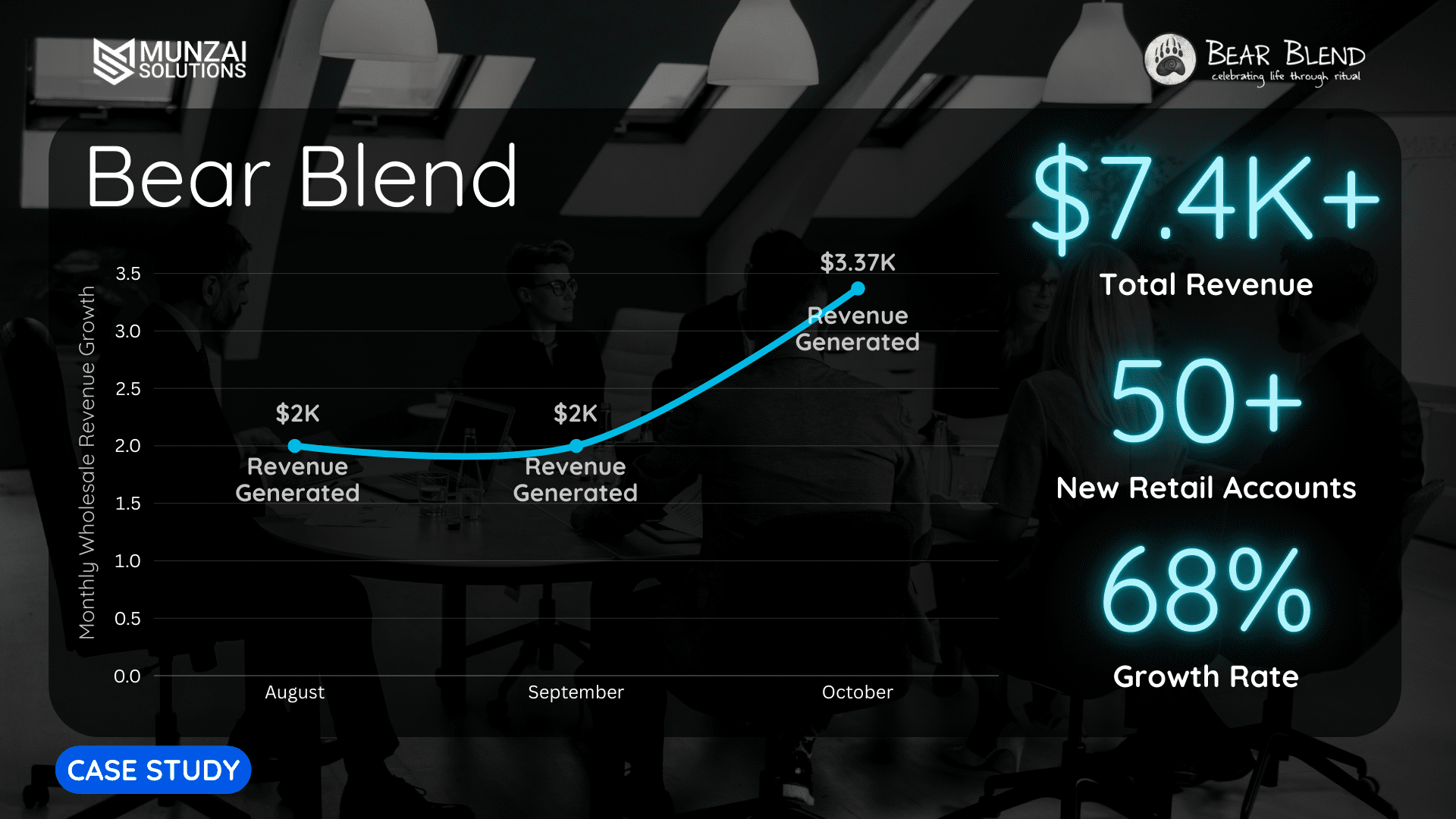
Peak Outage by the Numbers
• Downdetector Spike: Around 3 PM IST, there were around 800 reports in India alone, with 88% of them mentioning key chatbot malfunctions.
• Timeline for Recovery: o API return by 6:32 PM ET (3:02 AM IST the next day)
Voice chat and large-file functionality will be gradually reduced over the next few hours. Complete stability is expected by June 11 at noon in Asia.
Lessons Learned & Best Practices
1. Prepare Backup Tools.
There is no individual service which can promises 100 % uptime. Have backups of other AI providers, like Claude by Anthropic, Gemini by Google, or open-source LLMs, in case of critical applications.
Design for Degradation
Create backup plans when integrating AI into products. For instance, go to a streamlined FAQ page or a lightweight rule-based responder to handle basic queries in the event that a chatbot API fails.
3. Monitor Proactively
Add on synthetic-transaction monitoring which emulates user activity on a minute basis. This has the ability to detect anomalies quicker than passively collecting logs or ticketing reports.
4. Communicate Transparently
In case of an outage, users will remain confident when seeing fast updates, even when they are preliminary. It ought to be clearly signified which functions are offline and give reasonable estimates of restoration.
4. Memes & Tweets That Stole the Show
Laughter and frustration erupted on social media. The community’s inventiveness was evident in everything from “404: Inspiration Not Found” memes to tweets that made fun of AI taking a coffee break, reminding us that people still manage to connect and sympathise even when things are slow.

Moving Forward
As AI becomes ever more central to both personal productivity and enterprise workflows, outages like the one on June 10, 2025 serve as critical reminders: stellar performance under typical conditions must be matched by resilience under strain. Organizations and individual users alike should treat service interruptions not as rare “black swan” events but as inevitable challenges to plan for.
Incidents like the one on June 10, 2025, will serve as crucial reminders as AI continues to play a bigger part in organizational procedures and individual productivity: extraordinary performance under normal conditions must be coupled by poise under duress. Both organizations and individual users must assume that service interruptions are not infrequent “black swan” events that are impossible to predict but rather occurrences that must be planned around.
By implementing strong backup plans, keeping lines of communication open, and expanding our toolkit, we can create AI-powered systems that are reliable even in the event of an emergency.
Conclusion:
The June 10 outage served as a reminder that while performance is good to have, availability is crucial to the objective. You can prevent downtime from ruining your day by maintaining communication channels, building clever fallbacks, and diversifying your suppliers a little. You can also prevent sales failure by relying on Munzai Solutions.https://munzaisolutions.com/. A dynamic sales firm, Munzai Solutions focusses on both inbound and outbound sales tactics. We are excellent at providing customised sales solutions that boost lead generation and conversion rates, with an emphasis on maximising client acquisition and boosting revenue growth. Enhancing sales procedures, increasing customer engagement, and giving companies the resources they need to succeed in a cutthroat market are Munzai Solutions’ areas of expertise. Our results-oriented strategy guarantees clients quantifiable success and long-term expansion.